Nocturnus is live.
Today we are shipping a context server for AI agents — and it changes the math of the agent stack.
The bill nobody planned for
Here is what is happening inside every agent in production right now.
Every turn, your agent re-sends its full context to the model. System prompt. Tool definitions. Conversation history. Retrieved documents. All of it. Every time. The model already saw most of it three seconds ago. It does not matter. The token meter runs.
At low scale, this is invisible. At production scale, it is the line item that ate your gross margin.
We have watched companies move from a $500 proof-of-concept to an $847,000 monthly bill — without changing the model, without changing the architecture, without doing anything except adding users. A 1,694× increase. The financial model did not predict it. The dashboard did not warn about it. And the worst part is that most of those tokens were paying for the model to re-read what it had just read.
This is not a tuning problem. It is a structural one. And until today there has not been a clean architectural answer.
What Nocturnus is
Nocturnus is a context server.
It sits between your agent and your LLM. On every turn, it takes the agent’s current goal and works backward — through facts, through state, through history — to identify the minimum set of context required to support the next decision. It returns those facts. It returns nothing else.
Average context per turn drops from roughly 1,259 tokens to 221 on Claude Opus 4 — a 5.7× reduction measured on live API calls. Not through compression. Not through summarization. Through derivation — sending only what is logically necessary, because we know what is logically necessary.
This is not vector search. It is not a smarter chunker. It is not a longer cache. It is a different kind of computation: backward-chaining logical inference operating on a structured representation of agent state. The medieval Schoolmen had a word for the difference between recognition and reasoning. We do not need their word. We just need the architecture to work.
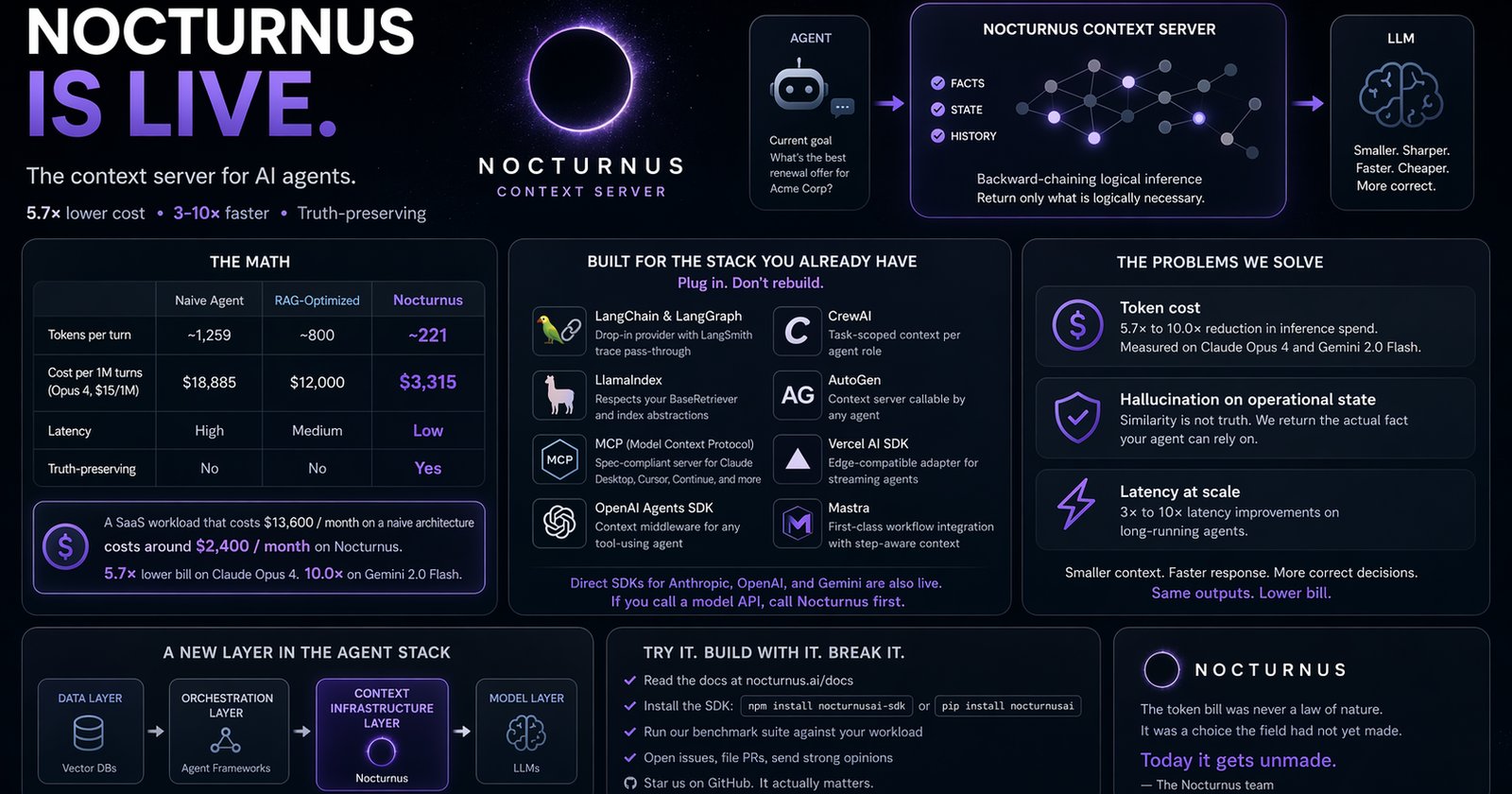
The math, briefly
| Naive agent | RAG-optimized | Nocturnus | |
|---|---|---|---|
| Tokens per turn | ~1,259 | ~800 | ~221 |
| Cost per 1M turns (Opus 4, $15/1M) | $18,885 | $12,000 | $3,315 |
| Latency | high | medium | low |
| Truth-preserving | no | no | yes |
A SaaS workload that costs $13,600 a month on a naive architecture costs around $2,400 a month on Nocturnus (Claude Opus 4, 1,000 req/hr). Same model. Same outputs. 5.7× lower bill. Gemini 2.0 Flash shows 10.0×.
That is not an optimization. That is a different category of product economics.
Built for the stack you already have
This is the part we want every framework, every agent platform, and every builder to hear.
Nocturnus is not a destination. It is a layer.
We are not asking you to migrate off LangChain. We are not asking you to leave LlamaIndex. We are not asking you to abandon AutoGen, CrewAI, Mastra, the Vercel AI SDK, or the OpenAI Agents SDK.
We are asking you to plug in.
Native integrations shipping today
- LangChain & LangGraph — drop-in
NocturnusContextProviderthat replaces or augments your retriever, with full LangSmith trace pass-through - LlamaIndex — context server backend that respects your existing
BaseRetrieverand index abstractions - MCP (Model Context Protocol) — fully spec-compliant server, usable by Claude Desktop, Cursor, Continue, and any MCP-aware client
- OpenAI Agents SDK — context middleware that wraps any tool-using agent without modifying its tool definitions
- CrewAI — task-scoped context resolution per agent role, so each crew member sees only what their job requires
- AutoGen — context server callable by any agent in a multi-agent conversation
- Vercel AI SDK — edge-compatible adapter for streaming agents on Next.js, Nuxt, and SvelteKit
- Mastra — first-class workflow integration with native step-aware context derivation
Direct SDK clients for Anthropic, OpenAI, and Gemini are also live. If you are calling a model API, you can call Nocturnus first.
The integration takes minutes. We are not asking you to rebuild your agent. We are asking you to put a smaller, sharper context in front of it.
What this means for the people building agents
If you are building an agent today, your three biggest hidden enemies are:
Token cost — which we have already addressed. 5.7× to 10.0× reduction in inference spend, measured on Claude Opus 4 and Gemini 2.0 Flash.
Hallucination on operational state — which vector retrieval cannot fix, because similarity is not truth. When your agent has to make a decision based on the current state of a customer record, a contract clause, or an inventory level, “the most semantically similar document” is the wrong abstraction. We return the actual fact.
Latency at scale — because every token in the prompt is a token the model has to attend to. Smaller context, faster response. We see 3× to 10× latency improvements on long-running agents.
Nocturnus helps with all three because all three are the same underlying problem: you are sending the model what it already knows, what it does not need, and what it cannot rely on. We send it what it needs and only what it needs. The model is faster, cheaper, and more correct because it is being asked a smaller, sharper question.
Your demos do not change. Your code mostly does not change. Your bill does.
The bigger picture
There is going to be a context infrastructure layer in the agent stack.
The same way there is a vector database layer. The same way there is an orchestration layer. The same way there is a model layer.
That layer does not exist yet as a recognized category. It is being built right now, by us and by a small number of others, in real time. Within eighteen months it will be obvious that it was always there — the way it is now obvious that vector databases were always going to be a category, even though that was not obvious in 2021.
We intend to be the default. Not by being a destination, but by being invocable from everywhere — from every framework, in every language, against every model. Infrastructure that everyone reaches for and nobody has to think about.
The model providers will not build this. They get paid by the token. The agent frameworks will not build this — it is not their job, and they need to remain provider-neutral. The vector database vendors are solving an adjacent problem, not this one.
It is going to be its own layer.
We are going to be that layer.
Try it. Build with it. Break it.
Nocturnus is live today.
- Read the docs at nocturnus.ai/docs
- Install the SDK for your stack:
npm install nocturnusai-sdkorpip install nocturnusai - Run our benchmark suite against your own workload — we publish the methodology, you publish the results
- Open issues, file pull requests, send us strong opinions
- Star us on GitHub. It actually matters.
For framework maintainers
If you maintain LangChain, LlamaIndex, CrewAI, Mastra, AutoGen, the Vercel AI SDK, or anything in this space — talk to us directly. We will meet you halfway and then some on a deeper integration. Co-author the adapter. Land it as a first-class option in your library. We are not protective. We are operational.
For early enterprise design partners
We are taking on a small number of design partners through Q3. If you are running an agent workload at meaningful scale and you want a custom benchmark + a 30-day pilot against your real traffic, reach out. We will tell you within a week whether we can save you money.
The token bill was never a law of nature. It was a choice the field had not yet made.
Today it gets unmade.
— The Nocturnus team