The agent stack is missing a layer.
We're building it.
The model providers won't build this — they get paid by the token. The agent frameworks won't build this — they need to stay provider-neutral. The vector database vendors are solving an adjacent problem. It's going to be its own layer, and it's going to be infrastructure.
Most tokens an agent spends are paying the model to re‑read what it just read.
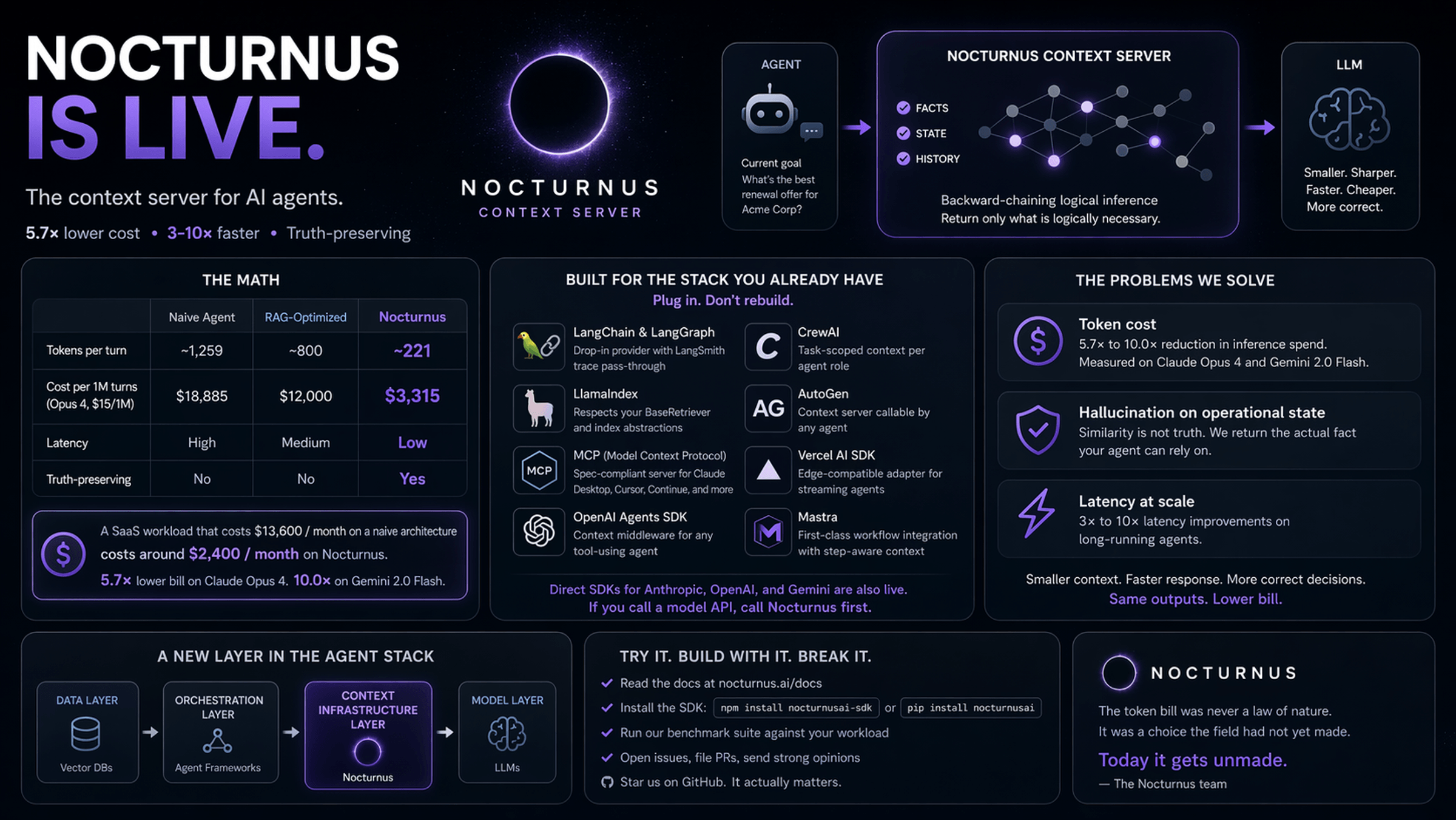
Every production agent today runs the same loop: take a goal, replay the entire conversation history, send it to the model, get back a response, repeat. At one user, it's invisible. At ten thousand users, the token bill is the line item that ate your gross margin. A $500 proof-of-concept becomes $847,000 per month without anyone changing a line of code.
The standard fixes don't fix it. Longer context windows make the prompt more expensive, not cheaper. Vector retrieval returns what looks similar, not what's true. Summarization compresses at the cost of fidelity. None of these are the same shape as the problem. The problem is that the agent sends the model information it already has, information it doesn't need, and information it can't rely on. The only correct answer is to send less, and to send the right less.
That's a computation. You can't retrieve your way into it, and you can't summarize your way into it. You have to reason about what's necessary, given the goal, given what's known. We are building a server that does exactly that — sitting between your agent and the LLM, deriving the minimum context required for the next decision, and returning only that.
Five commitments that shape every design decision.
Similarity is not truth.
The nearest vector is not the correct answer. Agents that decide based on "the most semantically similar document" will hallucinate on operational state — current contract terms, current inventory, current customer tier. We return facts the way a logic engine returns facts: because they are provable from what's known.
Determinism is a product feature.
The same query should return the same answer. Twice. A hundred times. In production, non-determinism is a bug surface you can't close. The reasoning layer should be something you can reason about — not a probability distribution you have to audit after the fact.
Measurement beats marketing.
Every cost and compression claim we publish is derived from a live API call we can point to — and you can reproduce. Our benchmarks are in the repo. Our math is on the calculations page. If a number we publish doesn't match a measurement, it's a bug.
Be a layer, not a destination.
Agent teams shouldn't have to migrate off LangChain, LlamaIndex, CrewAI, Mastra, AutoGen, the OpenAI Agents SDK, or the Vercel AI SDK to use us. We plug in. We are invocable from everywhere, in every language, against every model. Infrastructure that everyone reaches for and nobody has to think about.
Open source is the only defensible path.
Infrastructure that sits between an agent and its model will only get trusted if it's auditable. The core engine is BUSL-1.1 — free for internal use, converting to Apache 2.0 in 2030. The benchmarks, the math, and the decision logic are all in the open. If we get this wrong, you'll see it first.
Three numbers we care about, in order.
- Token reduction on real workloads.
Not synthetic benchmarks. Not cherry-picked conversations. The hard number an agent team can report to their CFO. Today, that number is 82–90% on live Claude Opus 4 and Gemini 2.0 Flash for a 15-turn product-support conversation. Next quarter, we want it higher, on harder workloads.
- Integration breadth, not depth.
We would rather be the default option in ten frameworks than the best option in one. Native adapters for LangChain, LlamaIndex, CrewAI, AutoGen, MCP, Mastra, the OpenAI Agents SDK, and the Vercel AI SDK — all invocable in one line. The number we track is time-to-first-context-call.
- Correctness under retraction.
When a fact becomes false, everything derived from it should become false with it. When a premise is removed, the context window should update without developer intervention. This is not a cost feature. It's a correctness feature — and it's why we built the truth-maintenance system before we shipped the cache.
This is a v0.3 product, shipping in public.
The core engine, the HTTP API, the MCP server, the Python and TypeScript SDKs, the LangChain adapter, and the live benchmark are all in the repo and running today. The roadmap — deeper integrations, better measurement, first-party hosted tier — is on GitHub.
We are a small team. We answer issues. We take pull requests. We take strong opinions from people building agents in production, because those are the people whose pain we are trying to solve.
Get involved.
SOURCE AVAILABLE · BUSL-1.1 → APACHE 2.0 (2030) · BUILDING IN PUBLIC
{kind=link}
Architecture, math, integrations, and mission — one image, print-friendly.
Try the engine
Docker one-liner, no signup. Running in 10 seconds.
Run the benchmark
Reproduce every number we publish — or break them.
Contribute
Issues, PRs, design-partner pilots. We read everything.
For partnerships, press, or design-partner pilots: hello@nocturnus.ai